 |
Berat Kurar-Barakat I hold a PhD degree in Computer Science from Ben-Gurion University. My PhD advisor was Prof. Jihad El-Sana. I have worked at his Visual Media Lab for five years on historical document image analysis using digital image processing and machine learning methods. I am presently a postdoctoral fellow in the Blavatnik School of Computer Science at Tel-Aviv University where I am hosted by Prof. Nachum Dershowitz. Our research focuses on document image analysis of Dead Sea Scrolls. |
 |
Qumran Segmentation Dataset (QSD) benchmarks the segmentation of ink and parchment regions in Dead Sea Scrolls fragment images. The dataset contains images of 20 fragments, including full-color images, first-band and last-band multispectral images, and normalized last-band images. All images are cropped to focus on the fragment and rice paper, excluding color bars, rulers, and plate numbers. Pixel values range from 0–255 for JPEGs and 0–65535 for TIFFs.
Explore the segmentation results or read the paper. |
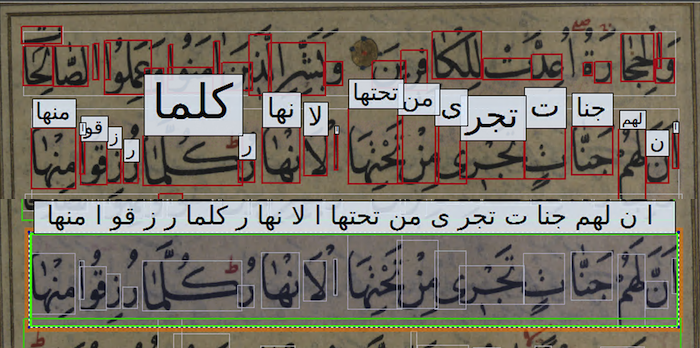 |
VML-HTR dataset: Handwritten Text Recognition dataset consists of five Arabic manuscripts annotated in subword level and text line level. Each manuscript contains 27000-35000 subwords and 1400-2000 text lines. Further statistics are available at here. Line level annotation is automatically generated using the subword level annotation from the VML-HD dataset. The ground truth is available in PAGE-XML format. |
 |
VML-HP dataset: Hebrew Paleography dataset consists of 537 document page images with labels of 15 script sub-types. Ground truth is manually created by a Hebrew paleographer at a page level. In addition, we propose a patch generation tool for extracting patches that contain an approximately equal number of text lines no matter the variety of fontsizes. The VML-HP dataset contains a train set and two test sets. The first is a typical test set, and the second is a blind test set for evaluating algorithms in a more challenging setting. |
 |
HHD dataset: Hebrew Handwritten dataset consists of natural handwritten Hebrew character images extracted from pangram paragraphs. Hence the dataset contains 26 classes balanced in terms of number of samples. Train set contains 3965 samples, test set contains 1134 samples. |
 |
VML-AHTE dataset: Arabic Handwritten Text Line Extraction dataset is a natural handwritten benchmark dataset for text lines with crowdy diacritics, touching and overlapping characters. It is fully labeled at line level by native Arabic speakers. The dataset contains 20 training pages and 10 test pages. Every document image has a corresponding ground truth in the form of pixel labels and PAGE xml. |
 |
The Pinkas dataset is a public historical document image dataset. It is the first dataset in medieval handwritten Hebrew and fully labeled at word, line and page level by an expert of historical Hebrew manuscripts. |
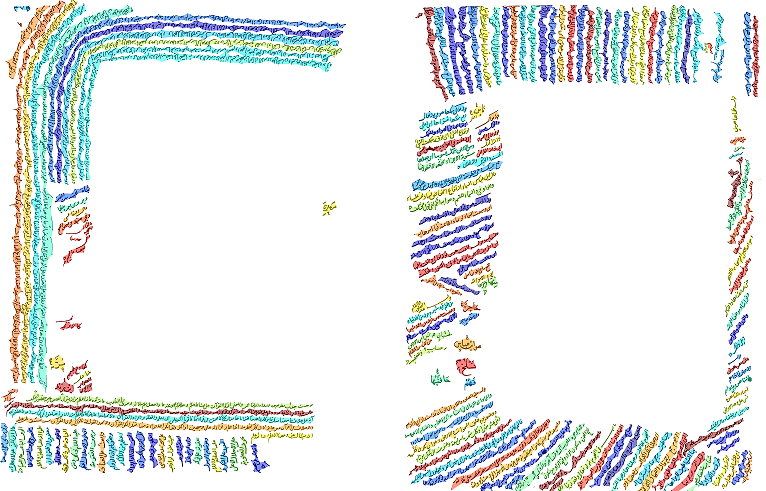 |
VML-MOC: Multiply oriented and curved handwritten text line dataset is a natural handwritten benchmark dataset for heavily skewed and curved text lines. These text lines are side notes added by scholars over the years on the page margins each time with a different orientation or sometimes in an extremely curvy form due to space constraints. The dataset contains 20 training pages and 10 test pages. Every document image has a corresponding ground truth in the form of pixel labels and PAGE xml. |
 |
Challenging text line dataset contains 30 pages from two different manuscripts. It is written in Arabic language and contains 2732 text lines where a considerable amount of them are multidirected, multi-skewed or curved. Ground truth where text lines were labeled manually by line masks, is also available in the dataset. |
 |
Complex layout dataset contains 32 document images from 2 manuscripts which were scanned at a private library located at the old city of Jerusalem and other samples which were collected from the Islamic manuscripts digitization project at Leipzig university library. |
Berat Kurar-Barakat and Nachum Dershowitz
Submitted to 2025 ICDAR - IJDAR Journal Track
[code] [QSD]
Berat Kurar-Barakat, Daria Vasyutinsky-Shapira, Sharva Gogawale, Mohammad Suliman and Nachum Dershowitz
2024 Computational Humanities Research Conference (CHR2024)
[poster] [slides] [code]
Daria Vasyutinsky-Shapira, Berat Kurar-Barakat, Sharva Gogawale, Mohammad Suliman and Nachum Dershowitz
2024 Eurographics Workshop on Graphics and Cultural Heritage (GCH2024)
[poster] [code]
Berat Kurar-Barakat and Nachum Dershowitz
2024 ICDAR Workshop on Computational Paleography (IWCP2024)
[slides] [code]
Daria Vasyutinsky-Shapira, Berat Kurar-Barakat, Mohammad Suliman, Sharva Gogawale and Nachum Dershowitz
2024 Digital Research Infrastructure for the Arts and Humanities (DARIAH2024)
[slides] [code]
Berat Kurar-Barakat, Mohammad Suliman, Sharva Gogawale, Daria Vasyutinsky-Shapira and Nachum Dershowitz
2024 Digital Humanities Conference (DH2024)
[poster] [code]
Berat Kurar-Barakat, Daria Vasyutinsky-Shapira, Sharva Gogawale, Mohammad Suliman and Nachum Dershowitz
2024 Israel Data Science and AI Initiative Conference (IDSAI2024)
[poster] [code]
Daria Vasyutinsky-Shapira, Berat Kurar-Barakat, Mohammad Suliman, Sharva Gogawale and Nachum Dershowitz
2024 Association for Jewish Studies (AJS2024)
[code]
Sharva Gogawale, Luigi Bambaci, Berat Kurar-Barakat, Daria Vasyutinsky-Shapira, Daniel Stökl Ben Ezra and Nachum Dershowitz
2024 Magazén International Journal for Digital and Public Humanities
[code]
Bronson Brown-deVost, Berat Kurar-Barakat and Nachum Dershowitz
2023 Preprint
[code]
Ahmad Droby, Berat Kurar-Barakat, Reem Alaasam, Boraq Madi, Irina Rabaev, Jihad El-Sana
2022 Signals Journal, MDPI
Ahmad Droby, Daria Vasyutinsky Shapira, Irina Rabaev, Berat Kurar-Barakat, Jihad El-Sana
2022 Journal of Imaging, MDPI
Ahmad Droby, Irina Rabaev, Daria Vasyutinsky Shapira, Berat Kurar-Barakat, Jihad El-Sana
2022 13th IAPR International Workshop on Document Analysis Systems (DAS)
Daria Vasyutinsky Shapira, Irina Rabaev, Ahmad Droby, Berat Kurar-Barakat and Jihad El-Sana
Jewish Studies in the Digital Age (DH2022)
[code]
Berat Kurar-Barakat, Ahmad Droby, Raid Saabni, and Jihad El-Sana
2021 International Conference on Document Analysis and Recognition (ICDAR)
[slides] [code]
Ahmad Droby, Berat Kurar-Barakat, Daria Vasyutinsky Shapira, Irina Rabaev, Jihad El-Sana
2021 International Conference on Document Analysis and Recognition (ICDAR)
[code]
Berat Kurar-Barakat, Rafi Cohen, Ahmad Droby, Irina Rabaev and Jihad El-Sana
2021 Applied Sciences Journal, MDPI
[code]
Daria Vasyutinsky, Irina Rabaev, Berat Kurar-Barakat, Ahmad Droby, and Jihad El-Sana
2020 Twin Talks: Understanding and Facilitating Collaboration in Digital Humanities
[slides] [code]
Berat Kurar-Barakat, Ahmad Droby, Rym Alasam, Boraq Madi, Irina Rabaev, Raed Shammes and Jihad El-Sana
2020 25th International Conference on Pattern Recognition (ICPR)
[code] [poster]
Berat Kurar-Barakat, Ahmad Droby, Rym Alasam, Boraq Madi, Irina Rabaev, and Jihad El-Sana
2020 2nd International Workshop on Pattern Recognition for Cultural Heritage (PatReCH)
[slides] [code]
Ahmad Droby, Berat Kurar-Barakat, Boraq Madi, Rym Alasam, and Jihad El-Sana
2020 17th International Conference on Frontiers in Handwriting Recognition (ICFHR)
[code]
Irina Rabaev, Berat Kurar-Barakat, Alexendar Churkin, and Jihad El-Sana
2020 17th International Conference on Frontiers in Handwriting Recognition (ICFHR)
[code] [poster]
Berat Kurar-Barakat, Irina Rabaev, and Jihad El-Sana
2019 International Conference on Document Analysis and Recognition (ICDAR)
[poster] [code]
Berat Kurar-Barakat, Rafi Cohen, Irina Rabaev, and Jihad El-Sana
2019 3rd International Workshop on Arabic and derived Script Analysis and Recognition (ASAR)
[slides] [code]
Reem Alaasam, Berat Kurar-Barakat, and Jihad El-Sana
2019 International Conference on Document Analysis and Recognition (ICDAR)
[poster] [code]
Berat Kurar-Barakat, Ahmad Droby, Majeed Kassis, and Jihad El-Sana
2018 16th International Conference on Frontiers in Handwriting Recognition (ICFHR)
[poster] [code]
Berat Kurar-Barakat, Reem Alaasam, and Jihad El-Sana
2018 13th IAPR International Workshop on Document Analysis Systems (DAS)
[poster] [pitch] [code]
Berat Kurar-Barakat and Jihad El-Sana
2018 2nd International Workshop on Arabic Script Analysis and Recognition (ASAR)
[slides] [code]
Alaa Abdalhaleem, Berat Kurar-Barakat, and Jihad El-Sana
2018 2nd International Workshop on Arabic Script Analysis and Recognition (ASAR)
[slides]
Reem Alaasam, Berat Kurar-Barakat, and Jihad El-Sana
2018 2nd International Workshop on Arabic Script Analysis and Recognition (ASAR)
Reem Alaasam, Berat Kurar-Barakat, and Jihad El-Sana
2017 1st International Workshop on Arabic Script Analysis and Recognition (ASAR)
Berat Kurar-Barakat and Nachum Dershowitz
11.07.2024
Berat Kurar-Barakat, Sharva Gogawale, Mohammad Suliman, Daria Vasyutinsky-Shapira and Nachum Dershowitz
29.01.2024
Berat Kurar-Barakat, Sharva Gogawale, Mohammad Suliman, Daria Vasyutinsky-Shapira and Nachum Dershowitz
12.12.2023
Berat Kurar-Barakat and Nachum Dershowitz
24.07.2023
Berat Kurar-Barakat and Nachum Dershowitz
[code]
01.08.2022
Winner Team of Page Segmentation Track
Berat Kurar-Barakat, Ahmad Droby, and Jihad El-Sana
[results] [code]
Winner Team of Classification Track
Ahmad Droby, Berat Kurar-Barakat, and Jihad El-Sana
[results] [code]