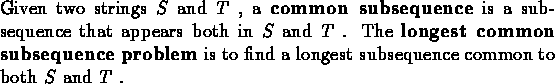The problem of Longest Common Subsequence can be modeled and solved
using the optimal alignment algorithm with the following scoring:
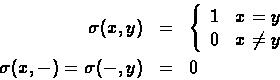
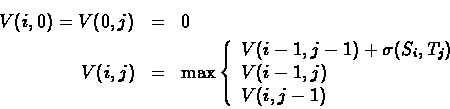
Each character in the string S can be align with the same character in the string T or with a space in T (in this case no substitution is done). Since the goal is to find maximum length, character matched are valued as '1', while a space match is valued '0'.